Visual Intelligence & the Data of Emotions

Over 6 billion images uploaded daily. Every one of them has some value to someone.
Signal vs. Noise
The system acts as a filter for the world's 6 billion daily images, built on a fundamental premise regarding crowd behavior.The Engine
Once an anomaly was detected, the system needed to understand what it was seeing. Running on a custom Python and Node.js architecture, proprietary CNN-driven feature extraction models deconstructed the influx of imagery. The system mapped these inputs into a shared latent space, turning a chaotic stream of pixels into structured, queryable intelligence.From Pixels to Patterns
While standard AI stopped at identifying "things"—a car, a crowd—Pixt was architected to understand meaning. Pixt used a translation layer that dissected images and video content across multiple semantic dimensions: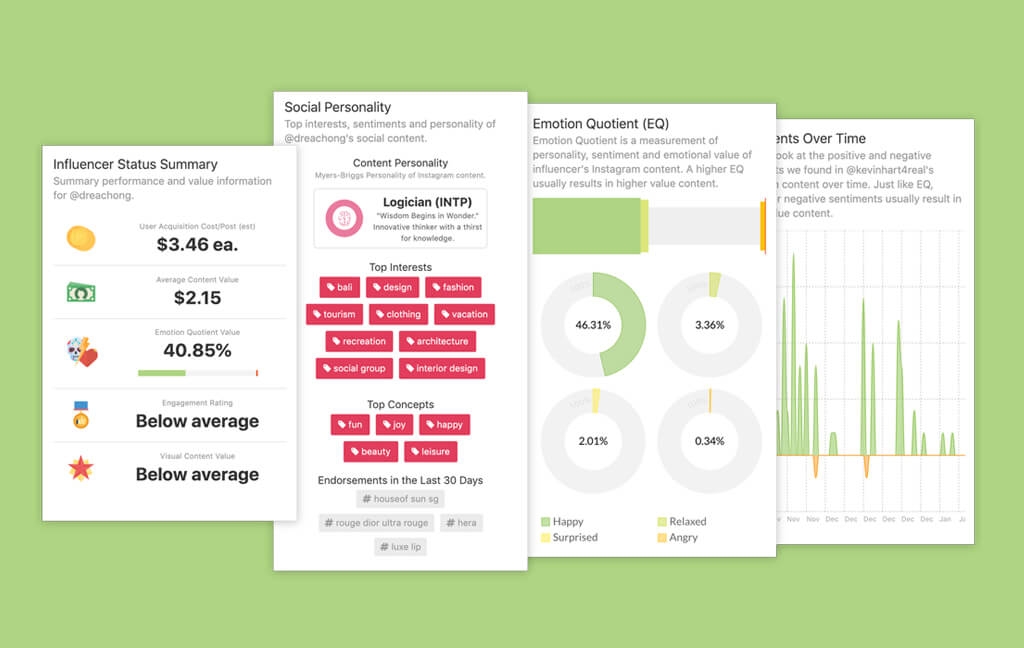
Semantic Object Detection: It mapped physical entities to conceptual roles. The system didn't just detect a "uniform" or "suit", it recognized the symbols of authority.
Contextual Vector Embeddings: By analyzing people, places, lighting, composition, and other variables, it determined emotional valence—distinguishing the visual signature of chaos from celebration.
Relational Inference: It decoded narrative geometry. For example, a megaphone facing a crowd is ambiguous. Pixt reranks the context against cluster-wide sentiment to confirm if it's detecting performance or dissent.
The Interface: A Trading Terminal for Reality
The dashboard was designed as a "financial trading terminal for events." It prioritized volatility and velocity over vanity metrics.Instead of tracking engagement, it tracked the intensity of visual conversation in specific geospatial zones. Real-time "valuations" were assigned to topics and locations based on the density and sentiment of incoming imagery. This allowed analysts to spot rising events—whether a protest in a city center or a product launch at a convention—and watch the visual narrative evolve in real-time.
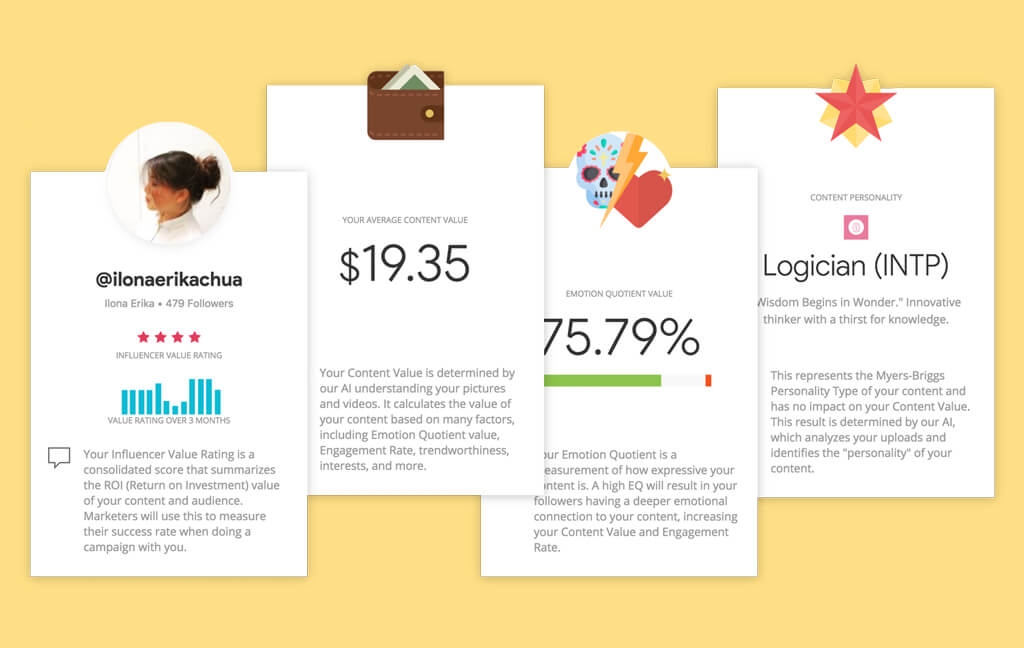

Automated Intelligence. The system used generative text workflows to make intelligence actionable. It could ingest clusters of images from breaking events and programmatically compose headlines and summaries—acting as a data-driven journalist that bridged visual signals to human-readable narrative. This turned raw detection into actionable intelligence without manual interpretation.
Key Outcomes
Pixt moved the needle on how we understand visual data. It wasn't just about identifying objects; it was about quantifying the speed of culture. By proving that global events could be detected through imagery alone, the platform established "visual velocity" as a critical signal for newsrooms, public safety, and competitive intelligence. The work secured significant financial backing and legal protection for its core IP, validating the thesis that the future of search is visual, real-time, and semantic.Create
What's
Next.
Ready to ship? Let's talk scope.
Email us
© 2026 Alucrative
| |